We present some examples from the collected DailyPersuasion dataset, and responses generated by different methods.
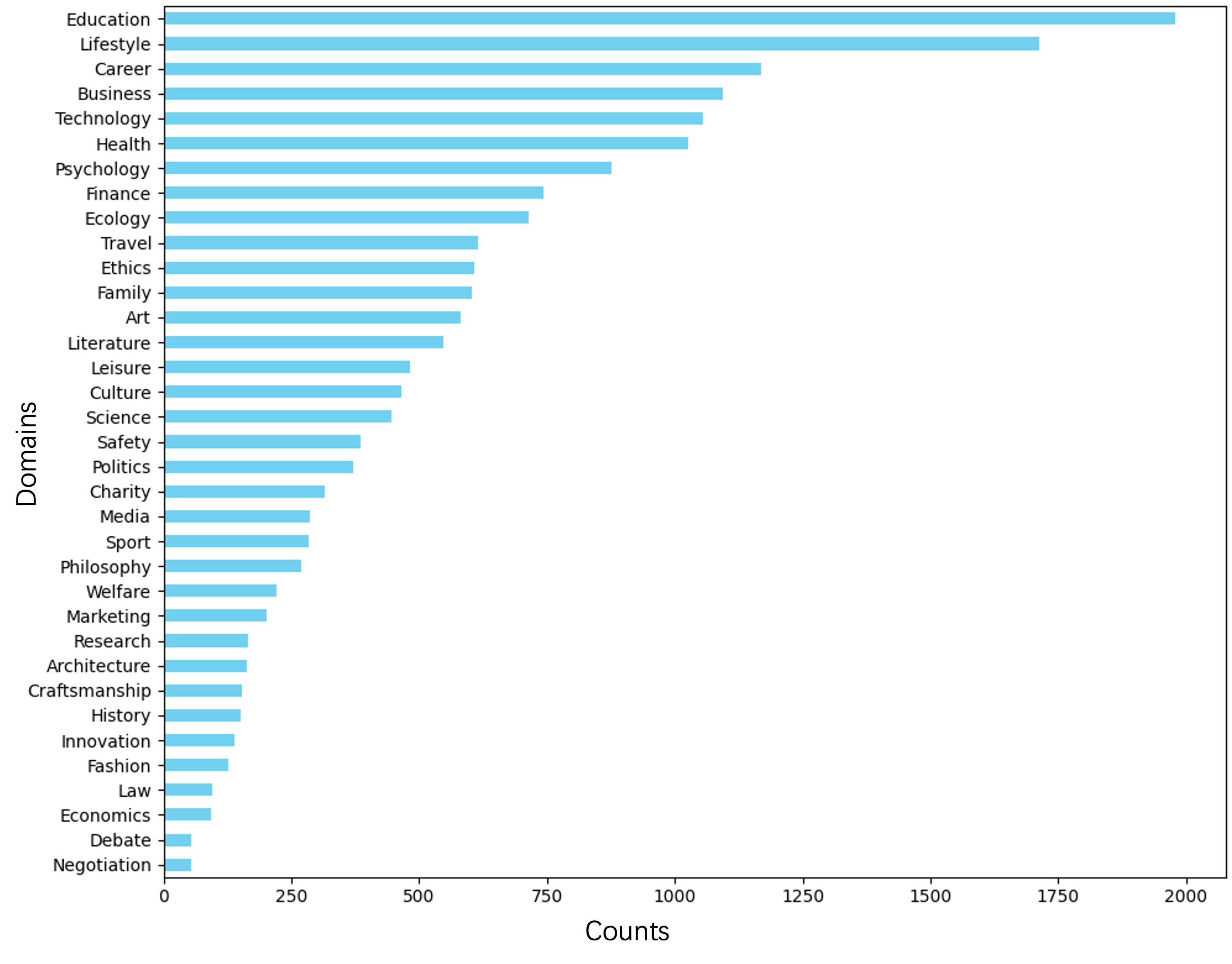
Figure 1. The distribution of the number of scenarios in different domains is counted. It should be noted that a persuasion scenario may belong to multiple domains.

Figure 2. Word cloud charts of persuasion strategies in selected domains from the DailyPersuaion dataset. It can be seen that in addition to those high-frequency general strategies, each domain has some unique persuasion strategies.